Tool Category:
Low-CodeSummary
GREMLIN is a low-code platform built to deliver powerful, bespoke legal analytics and data science pipelines directly to non-technical end-users. While building data pipelines for legal analytics is complex, GREMLIN provides for two types of users - legal engineers and lawyers. The interface for lawyers is a simple, point-and-click interface that lets them select a pipeline, add documents and get an e-mail notification upon completion. There's no need for them to learn how to code. Legal engineers, on the other hand, have access to a powerful Python coding environment and drag-and-drop visual data pipeline editor.
The legal engineering interface lets legal engineers quickly mix and match modular, python-based contract analytics modules (called ""scripts"") to extract data from or push data into legal documents and templates. Legal data pipelines are built of multiple Python-based scripts. Each script is written in Python and any Python library can be installed on the system. Scripts can be combined into data pipelines, with each script having access to 1) the source document file, 2) the source document text (extracted by Apache Tika), and 3) the results of previous nodes in the pipelines. Upon completion, pipelines can notify users by e-mail or they can send notifications to external APIs.
You can write scripts and pipelines yourself using pure Python code, or you can use pre-built modules. Either way, these scripts can then be re-used and combined into complex workflows that let you achieve legal tasks for your attorneys and clients at scale.
The GREMLIN project is still in beta, but the fully-functioning beta release comes with sample scripts and pipelines that let you:
- Create Documents - using Python's rich ecosystem, GREMLIN lets you push data into .docx or .doc templates and produce finished documents.
- Analyze & Extract Contract Clauses - using classifiers trained on the Atticus Project's labeled contract data, GREMLIN will take a PDF contract, analyze the legal provisions and return an annotated PDF to your.
- Cluster Documents - using basic sklearn K-means clustering, GREMLIN can take a collection of documents, group them by similarity and returns these in a zip file.
- OCR Documents - using another open source library, OCRUSREX, GREMLIN can take unsearchable, image only PDFs and return new versions with embedded, searchable text layers.
- Extract Data from Form Documents - using simple regex patterns, GREMLIN can extract data from in bulk from template documents.
Screenshots
Easily Build Legal Data Extraction and Consumption Pipelines
Gremlin provides legal engineers with a frontend interface to quickly and easily create complex data pipelines. Because Gremlin is built with Python, it's trivially easy to leverage the NLP and data science capabilities of Python to interact with text. Gremlin lets you quickly create and edit Python-based "nodes" that consume raw text and data and then return processed data or documents. These nodes can be readily re-used or combined to create a modular set of components for text processing.
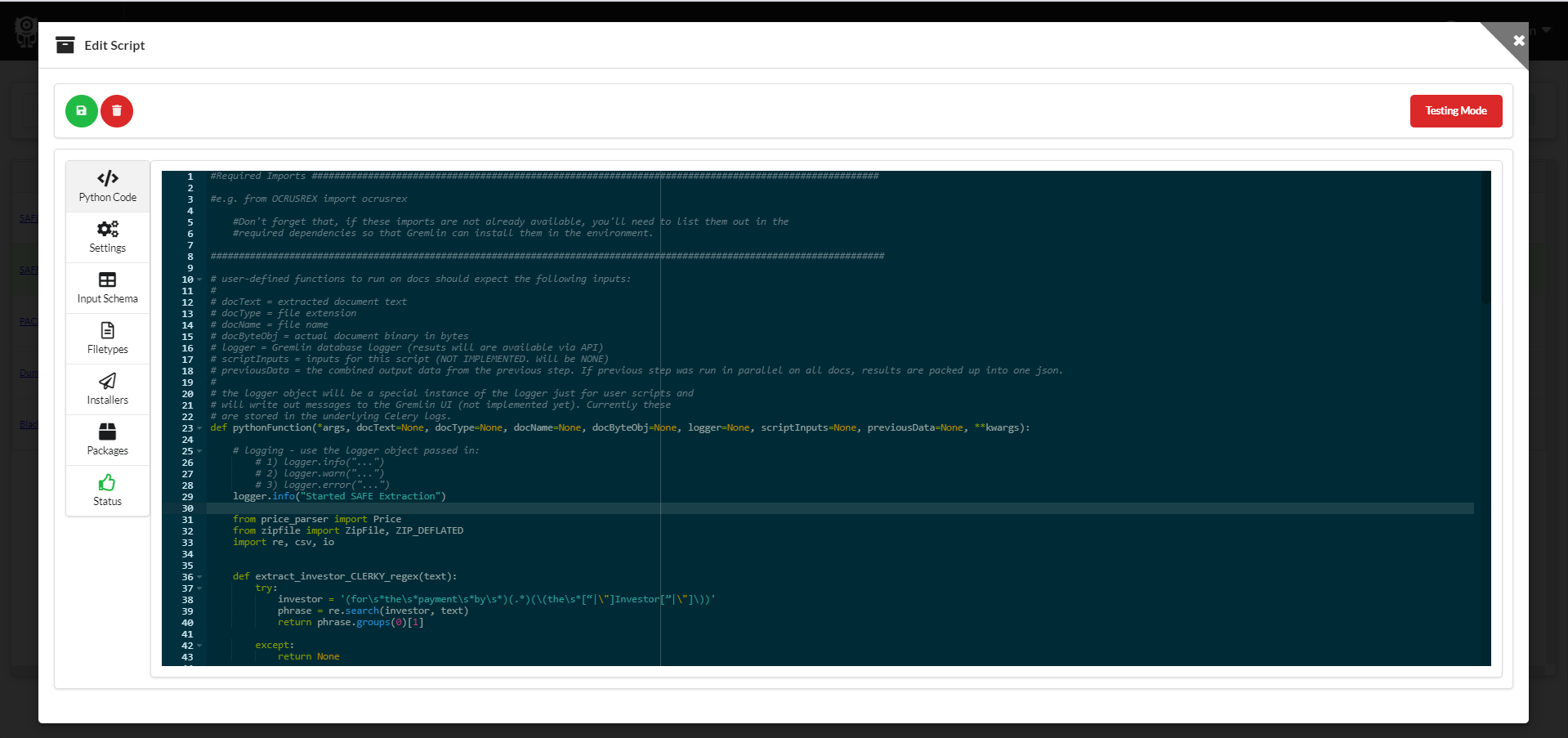
Built-in Cloud Code Editor for Python Scripts
Gremlin's backend is 100% Python, and the React-based frontend provides a built-in Python code editor.
Deliver Advanced Data Science and NLP to Non-Technical Users
Gremlin is designed to make it easy to delivery the expertise and insights of cutting-edge data science to non-technical users. It has a simple, self-service interface for lawyers and non-technical users to use pre-built document engineering pipeline. Since pipelines are exportable and importable, you can load pre-built pipelines created by Open Source Legal or work with data scientists to create your own, custom pipelines and deliver them to non-technical users.